1.GraphQL
1.1 介绍
GraphQL 是一种 API 查询语言
GraphQL 是一种为 API 接口和查询已有数据运行时环境的查询语言. 它提供了一套完整的和易于理解的 API 接口数据描述, 给客户端权力去精准查询他们需要的数据, 而不用再去实现其他更多的代码, 使 API 接口开发变得更简单高效, 支持强大的开发者工具.
友情链接:
1.1.1 What is GraphQL?
正如副标题所说,GraphQL 是由 Facebook 创造的用于描述复杂数据模型的一种查询语言。这里查询语言所指的并不是常规意义上的类似 sql 语句的查询语言,而是一种用于前后端数据查询方式的规范。
1.1.2 Why using GraphQL?
当今客户端和服务端主要的交互方式有 2 种,分别是 REST 和 ad hoc 端点。GraphQL 官网指出了它们的不足之处主要在于:当需求或数据发生变化时,它们都需要建立新的接口来适应变化,而不断添加的接口,会造成服务器代码的不断增长,即使通过增加接口版本,也并不能够完全限制服务器代码的增长。
GraphQL 特性
- 首先,它是声明式的。查询的结果格式由请求方(即客户端)决定而非响应方(即服务器端)决定,也就是说,一个 GraphQL 查询结果的返回是同客户端请求时的结构一样的,不多不少,不增不减。
- 其次,它是可组合的。一个 GraphQL 的查询结构是一个有层次的字段集,它可以任意层次地进行嵌套或组合,也就是说它可以通过对字段进行组合、嵌套来满足需求。
- 第三,它是强类型的。强类型保证,只有当一个 GraphQL 查询满足所设定的查询类型,那么查询的结果才会被执行。
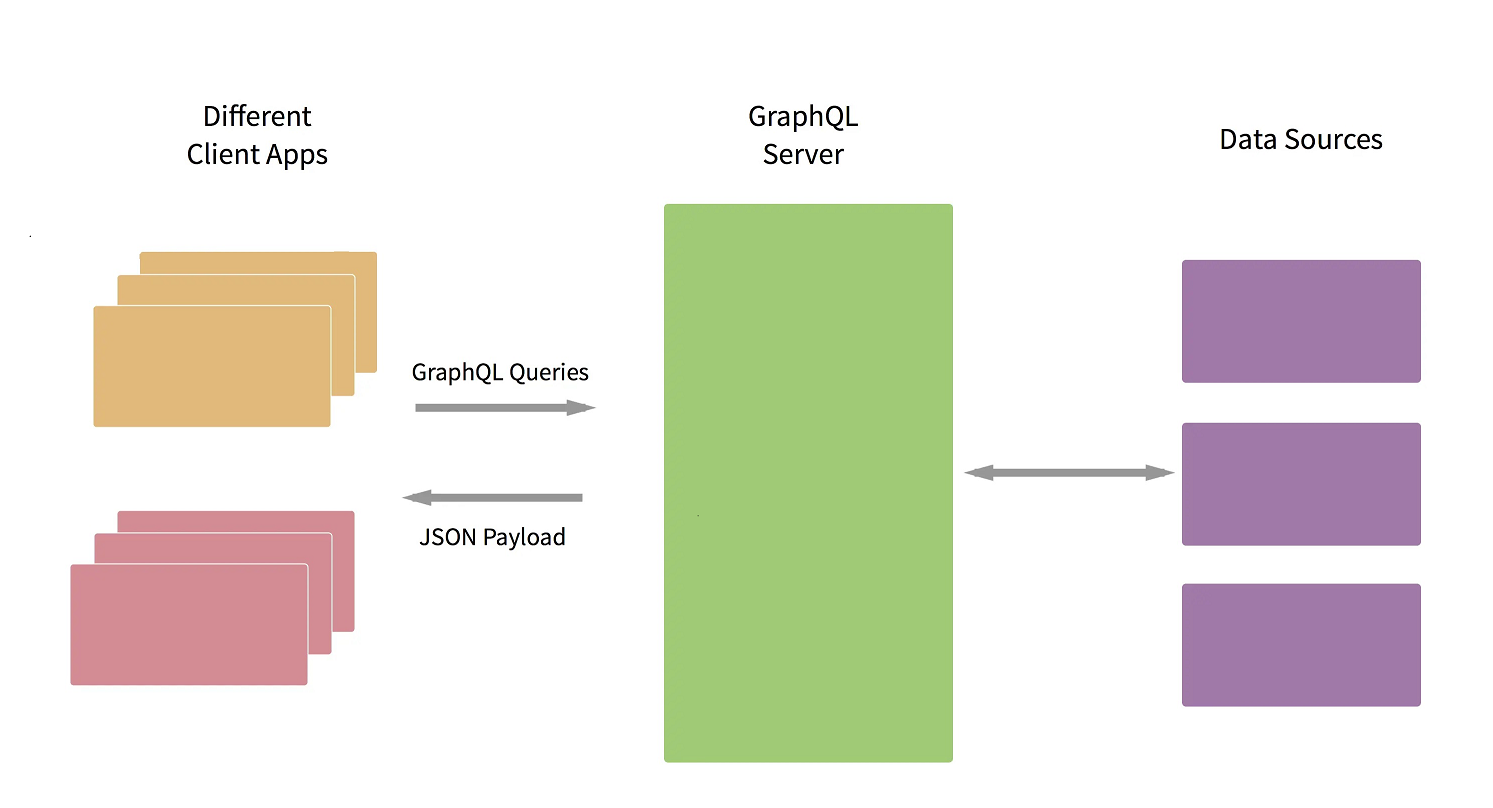
1.2 Node.js 环境简单用法
1.下载
GraphQL 规范的参考实现, 专为在 Node.js 环境中运行 GraphQL 而设计.
通过 命令行 执行 GraphQL.js hello world 脚本:
1 | npm install graphql |
2.创建 hello.js
然后执行 node hello.js.
hello.js源码:
1 | var { graphql, buildSchema } = require('graphql'); |
1.3 Express 运行
通过 Express 实现的 GraphQL 参考实现, 你可以联合 Express 运行或独立运行.
为了方便下面的步骤,我们在graphql文件夹中手动创建下面的目录结构,并安装指定的依赖
运行一个 express-graphql 安装项目依赖
1 | npm install express express-graphql graphql |
1.index.js代码
1 | const express = require('express') |
2.graphql/schema.js代码
1 | const { |
3.graphql/queries/fetchObjectData.js代码
先在graphql/queries文件夹下创建fetchObjectData.js文件, 并填入以下代码
1 | const { |
4.graphql/mutations/updateData.js代码
先在graphql/mutations文件夹下创建updateData.js文件, 并填入以下代码
1 | const { |
好了,到此为止,简单的GraphQL服务器就搭建好了,让我们来启动看看
1 | node index.js // 启动项目 |
然后我们在浏览器打开 http://localhost:3000/graphql 如下图所示
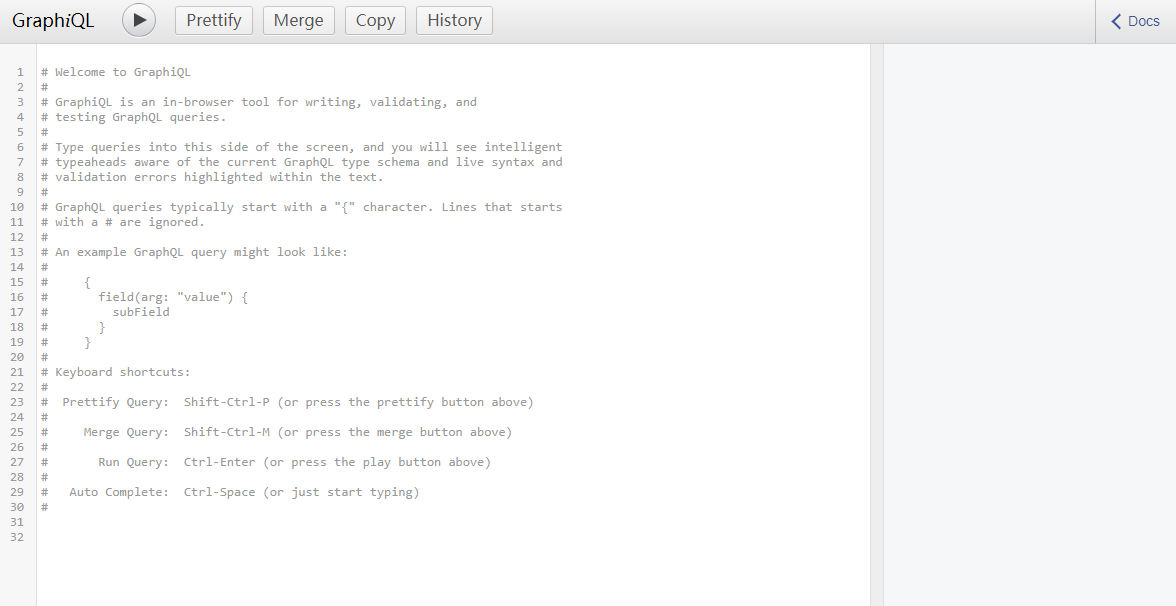
我们可以看到页面分为3栏,左边的是调用api用的,中间是调用api返回的结果 右边实际上就是我们刚才定义接口相关的东西,也就是api文档。
我们在左边粘贴以下代码
1 | query fetchObjectData { |
1.4 语法规范
1、导入GraphQL.js及类型
graphql 无论在定义接口参数和接口返回结果时, 都需要先定义好其中所包含数据结构的类型, 这不难理解,可以理解为我们定义的就是数据模型,其中常用的类型如下。
1 | const { |
2、定义schema
schema实例中,一般规范为
query: 定义查询类的接口
mutation: 定义修改类的接口
1 | new GraphQLSchema({ |
3、接口方法定义
1 | // 引用需要用到的数据类型 |
1.5 前后端交互(入门)
1、准备
1 | npm i --save express express-graphql graphql cors |
2.服务器端代码app.js
1 | var express = require('express'); |
3. 客户端代码index.html
1 |
|
1.6 总结
目前前后端的结构大概如下图。后端通过 DAO 层与数据库连接,服务于主要处理业务逻辑的 Service 层,为 Controller 层提供数据源并产出 API;前端通过浏览器 URL 进行路由命中获取目标视图状态,而页面视图是由组件嵌套组成,每个组件维护着各自的组件级状态,一些稍微复杂的应用还会使用集中式状态管理的工具,比如 Vuex、Redux、Mobx 等。前后端只通过 API 来交流,这也是现在前后端分离开发的基础。
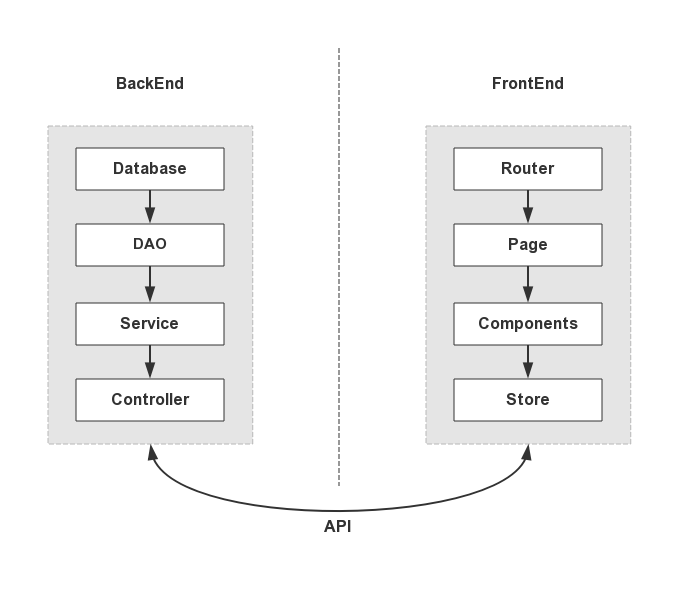
如果使用 GraphQL,那么后端将不再产出 API,而是将 Controller 层维护为 Resolver,和前端约定一套 Schema,这个 Schema 将用来生成接口文档,前端直接通过 Schema 或生成的接口文档来进行自己期望的请求。
经过几年一线开发者的填坑,已经有一些不错的工具链可以使用于开发与生产,很多语言也提供了对 GraphQL 的支持,比如 Java/Nodejs、Java、PHP、Ruby、Python、Go、C# 等。
一些比较有名的公司比如 Twitter、IBM、Coursera、Airbnb、Facebook、Github、携程等,内部或外部 API 从 RESTful 转为了 GraphQL 风格,特别是 Github,它的 v4 版外部 API 只使用 GraphQL。据一位在 Twitter 工作的大佬说硅谷不少一线二线的公司都在想办法转到 GraphQL 上,但是同时也说了 GraphQL 还需要时间发展,因为将它使用到生产环境需要前后端大量的重构,这无疑需要高层的推动和决心。
正如尤雨溪所说,为什么 GraphQL 两三年前没有广泛使用起来呢,可能有下面两个原因:
- GraphQL 的 field resolve 如果按照 naive 的方式来写,每一个 field 都对数据库直接跑一个 query,会产生大量冗余 query,虽然网络层面的请求数被优化了,但数据库查询可能会成为性能瓶颈,这里面有很大的优化空间,但并不是那么容易做。FB 本身没有这个问题,因为他们内部数据库这一层也是抽象掉的,写 GraphQL 接口的人不需要顾虑 query 优化的问题。
- GraphQL 的利好主要是在于前端的开发效率,但落地却需要服务端的全力配合。如果是小公司或者整个公司都是全栈,那可能可以做,但在很多前后端分工比较明确的团队里,要推动 GraphQL 还是会遇到各种协作上的阻力。
大约可以概括为性能瓶颈和团队分工的原因,希望随着社区的发展,基础设施的完善,会渐渐有完善的解决方案提出,让广大前后端开发者们可以早日用上此利器。